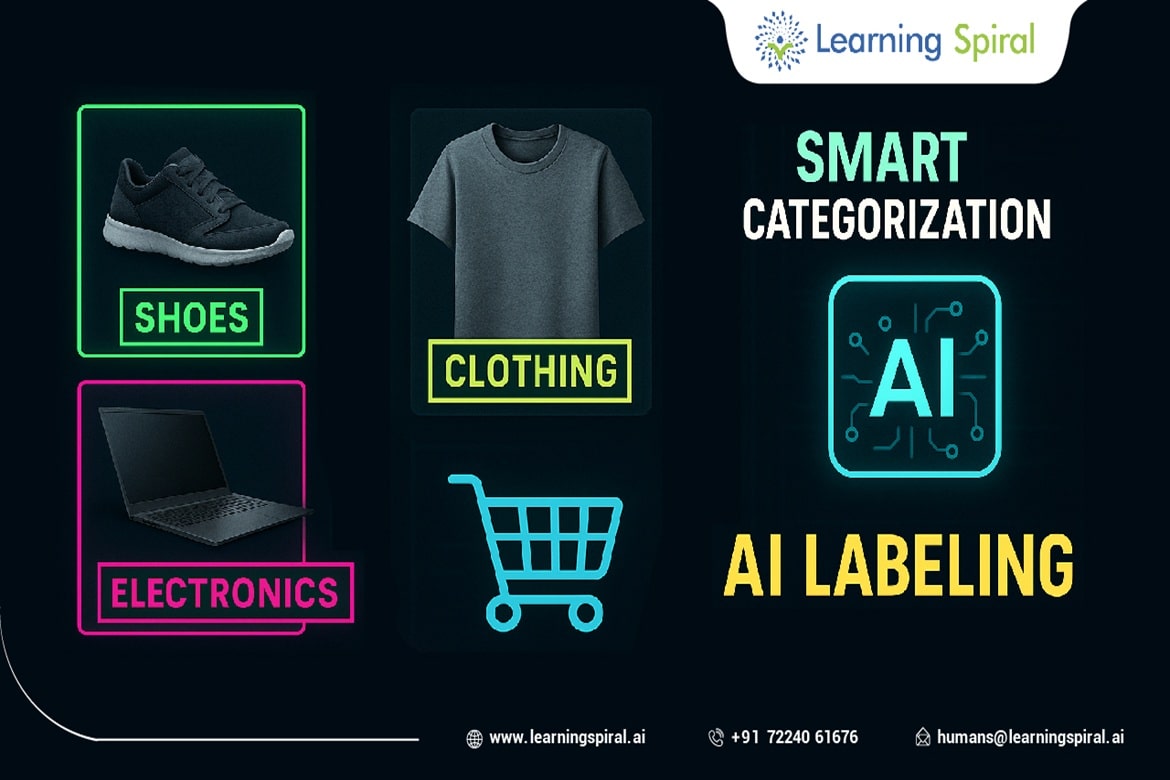
Building an advanced machine learning model capable of performing its denoted task to the tee is a complicated process. This difficult task is carried out via a set structure of codes and commands. One such process is the annotation of the data provided to the AI or machine learning model for research and other purposes.
If the source of the data is incomplete or incorrect, the complete understanding of the machine learning model gets wrecked. And that’s how important data annotation is for the successful uprising of machine learning models.

Why is data annotation so vital?
While traditional annotation methods remain essential, innovative techniques are pushing the boundaries of this critical process. These advancements not only streamline the process but also improve the quality and efficiency of AI development.
Let’s discuss this section in-depth:
- Ground Truth: Annotating data provides ground truth, the gold standard against which machine learning models measure their performance. Without accurate labels and classifications, algorithms will lack a clear direction to navigate commands or generate results.
- Feature Extraction: Think of annotations as signposts highlighting key features and patterns within the data. They guide the model’s learning process, helping it identify relevant information and differentiate between useful and irrelevant details.
- Generalizability: The broader and more diverse the annotated data, the more adaptable and generalizable the resulting model becomes. With a robust foundation of labeled data, algorithms can learn to apply their knowledge to new, unseen situations, making them truly valuable tools.
- Error Mitigation: Annotations act as checkpoints, helping identify and correct errors in the learning process. By analyzing inconsistencies and misinterpretations, we can refine the data and adjust the model’s training to improve its accuracy and avoid biases.
The Collaboration of the AI and the human touch:
Data annotation is not solely a machine-driven endeavor. Human expertise remains irreplaceable, especially for complex tasks like sentiment analysis, nuance detection, and identifying ethical considerations. The collaboration between humans and machines, combining human judgment with automated workflows, is the true recipe for success.
In conclusion, data annotation is not just a technical procedure; it’s an investment in the future of AI. By prioritizing a high-quality, diverse, and innovative annotation process, we lay the foundation for robust, reliable, and truly impactful machine learning models. Remember, a strong foundation is the key to building a magnificent castle of AI potential.