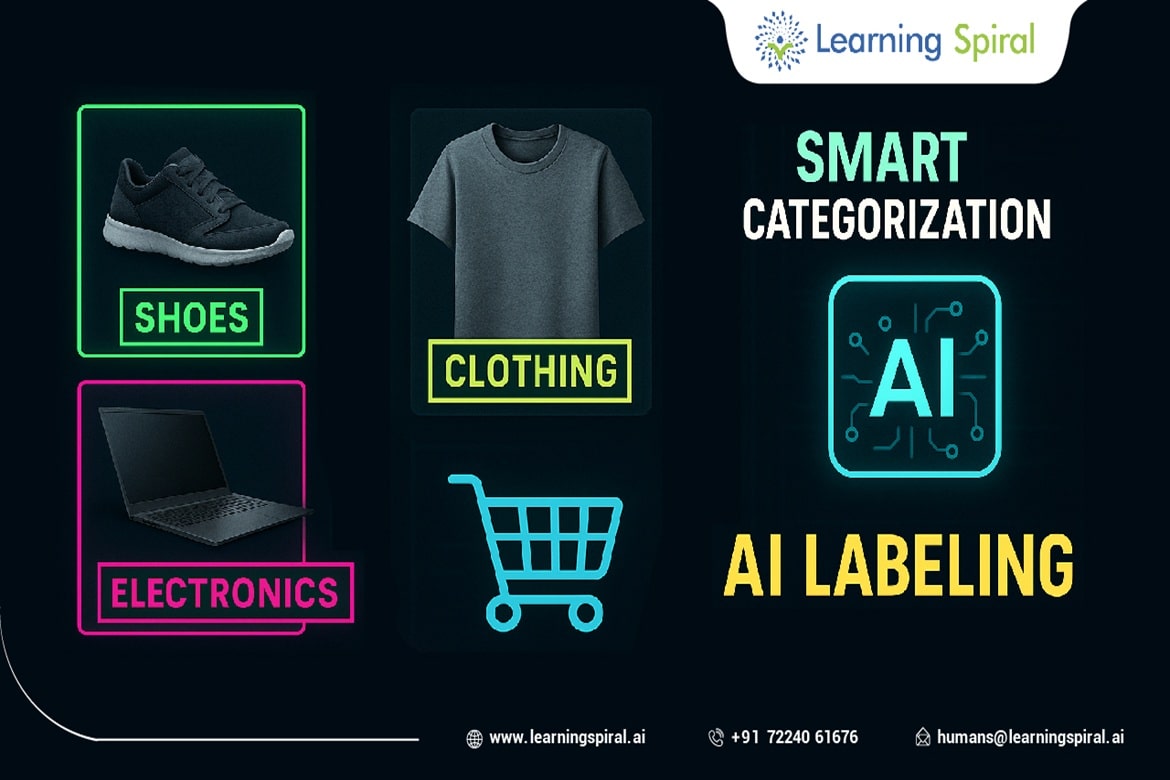
Natural Language Processing (NLP) is a field of artificial intelligence that focuses on enabling computers to understand, interpret, and generate human language.
At the heart of NLP lies the crucial task of data annotation, which involves labeling or tagging raw text data with specific information.
This annotated data serves as the foundation for training NLP models, guiding them to learn patterns, structures, and meanings within language.
The Importance of High-Quality Annotations 
The quality of NLP models is directly tied to the quality of the annotated data they are trained on. Accurate and consistent annotations provide the models with the necessary information to learn from, enabling them to perform tasks such as:
- Machine Translation: Translating text from one language to another.
- Sentiment Analysis: Determining the sentiment expressed in text (positive, negative, or neutral).
- Named Entity Recognition: Identifying named entities like persons, organizations, or locations.
- Text Classification: Categorizing text into predefined classes or topics.
Question Answering: Answering questions based on given text.
Common Types of NLP Data Annotation
- Tokenization: Breaking text into individual words or tokens.
- Part-of-Speech Tagging: Assigning grammatical categories (e.g., noun, verb, adjective) to words.
- Named Entity Recognition: Identifying and labeling named entities (e.g., persons, organizations, locations).
- Dependency Parsing: Analyzing the grammatical structure of sentences by identifying dependencies between words.
- Coreference Resolution: Identifying and resolving references to the same entity within a text.
- Sentiment Analysis: Labeling text based on its sentiment (positive, negative, or neutral).
Beyond the Basics: Advanced Annotation Techniques
While the aforementioned techniques form the foundation of NLP data annotation, there are more advanced techniques that can be used to address specific challenges and improve model performance:
- Event Extraction: Identifying and classifying events or actions described in text.
- Relation Extraction: Identifying relationships between entities or concepts.
- Dialogue Annotation: Labeling interactions between multiple speakers in a conversation.
- Discourse Analysis: Analyzing the structure and organization of text, including coherence and cohesion.
Challenges and Best Practices
- Ambiguity and Context: Natural language is inherently ambiguous, and understanding context is crucial for accurate annotation.
- Subjectivity: Some tasks, such as sentiment analysis, involve subjective judgments that can vary between annotators.
- Data Quality: Ensuring the consistency and accuracy of annotations is essential for training effective models.
To address these challenges, organizations often employ a combination of human annotators and automated tools. Human annotators can provide expert judgment and handle complex cases, while automated tools can streamline the process and improve efficiency.
Additionally, best practices such as clear guidelines, quality control measures, and version control can help ensure the quality and consistency of annotated data.
The Future of NLP Data Annotation
As NLP continues to advance, the demand for high-quality annotated data will only increase. Emerging techniques such as active learning and transfer learning hold promise for improving the efficiency and accuracy of data annotation. Additionally, the development of more sophisticated annotation tools and platforms can help streamline the process and make it more accessible to researchers and developers.
In conclusion, NLP data annotation is a critical step in the development of language-understanding AI systems. By understanding the different types of annotations, addressing the challenges, and leveraging advanced techniques, organizations can create powerful and accurate NLP models that can revolutionize various industries.