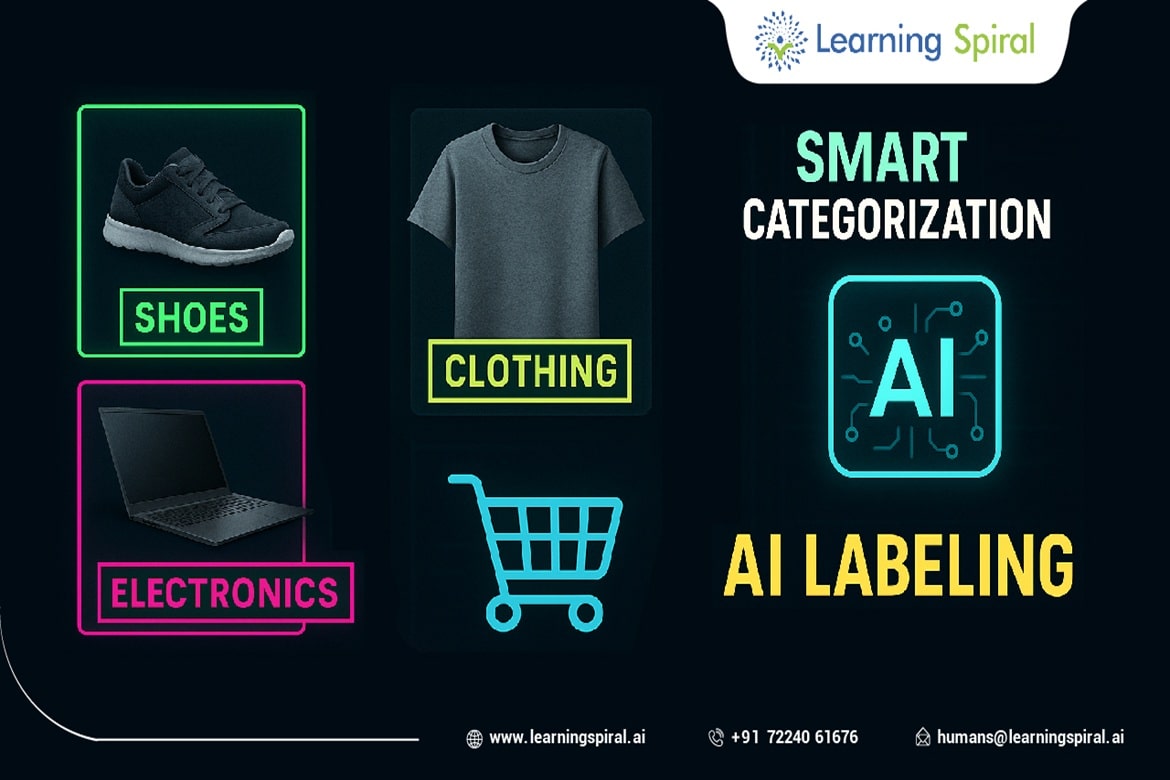
Data annotation, a cornerstone of machine learning and artificial intelligence, has evolved into a critical process for training algorithms to understand and interpret data.
This practice involves labeling or tagging raw data with meaningful information, enabling machines to learn patterns and make accurate predictions. Let’s delve into the origins of data annotation and explore its various types.
The Early Days: Manual Annotation 
The roots of data annotation can be traced back to the early days of computer vision and natural language processing. Researchers would painstakingly label images, text, or audio data by hand, providing the algorithms with a foundation to learn from.
This manual process was time-consuming and labor-intensive, limiting the scale and complexity of the models that could be trained.
The Rise of Crowdsourcing
As the demand for annotated data grew exponentially with advancements in AI, crowdsourcing emerged as a viable solution. Many platforms connected businesses with a vast global workforce willing to complete annotation tasks. This approach significantly accelerated the annotation process and reduced costs, enabling the development of more sophisticated models.
Types of Data Annotation
Data annotation encompasses a wide range of techniques, each tailored to specific applications and data types. Some of the most common types include:
- Image Annotation:
This involves labeling objects, regions, or features within images. Common techniques include:
- Object Detection: Identifying and localizing objects in images.
- Image Segmentation: Dividing images into meaningful regions.
- Landmark Detection: Locating specific points or landmarks within images.
- Text Annotation:
This involves tagging text with labels such as entities, sentiment, or parts of speech. Examples include:
- Named Entity Recognition: Identifying named entities like persons, organizations, or locations.
- Sentiment Analysis: Determining the sentiment expressed in text (positive, negative, or neutral).
- Part-of-Speech Tagging: Assigning grammatical categories to words.
- Audio Annotation:
This involves transcribing audio data, labeling speech events, or identifying sounds. Examples include:
- Speech-to-Text Transcription: Converting spoken language into written text.
- Speaker Identification: Identifying individual speakers in audio recordings.
- Sound Event Detection: Locating and classifying specific sounds.
- Video Annotation:
This involves labeling objects, events, or actions within videos. Examples include:
- Activity Recognition: Identifying human activities in videos.
- Object Tracking: Tracking the movement of objects over time.
- Event Detection: Detecting specific events or occurrences.
- 3D Annotation:
This involves labeling objects or regions in 3D data, such as point clouds or CAD models. Examples include:
- 3D Object Detection: Identifying and localizing objects in 3D space.
- Semantic Segmentation: Assigning semantic labels to points or regions in 3D data.
The Future of Data Annotation
As AI continues to evolve, the demand for high-quality annotated data will only increase. While crowdsourcing has been a valuable tool, there is a growing need for more advanced techniques to address the challenges of complex data and ensure data quality. Automation and active learning are emerging as promising approaches, combining human expertise with machine learning algorithms to improve efficiency and accuracy.
In conclusion, data annotation has played a pivotal role in the development of AI and machine learning. From its humble beginnings in manual labeling to the rise of crowdsourcing and automation, data annotation continues to evolve to meet the ever-increasing demands of AI applications.