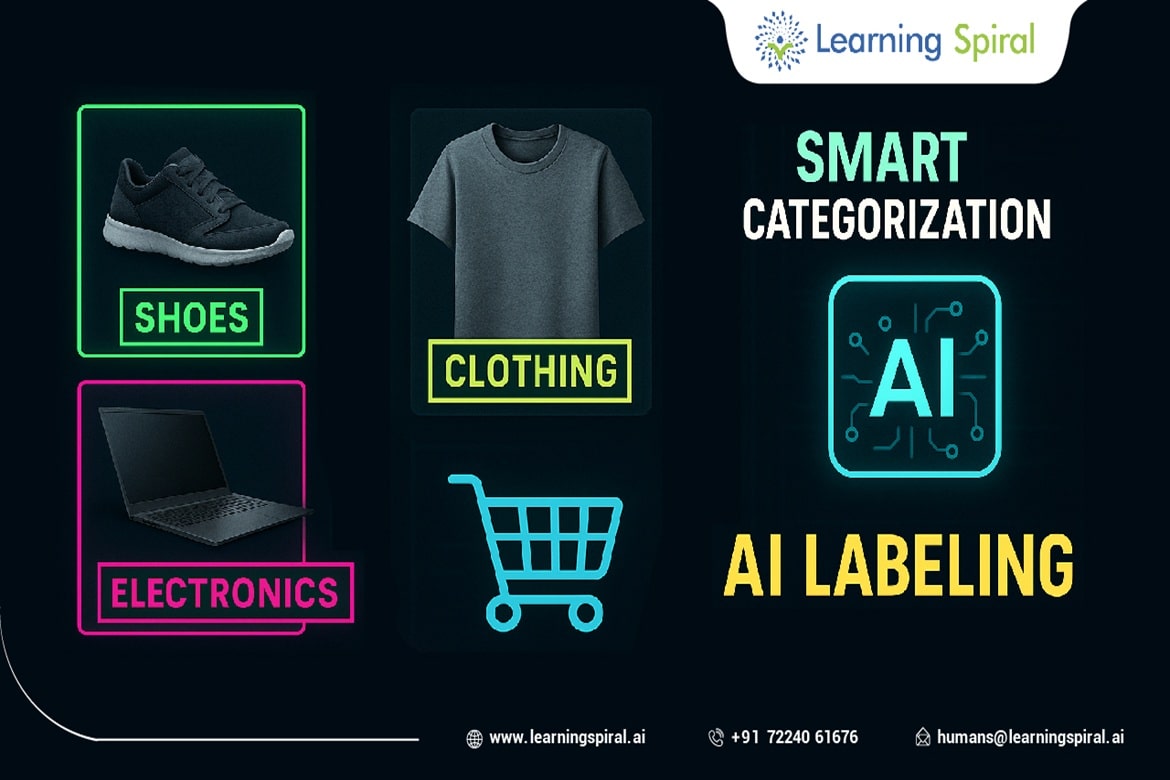
Natural Language Processing (NLP) is a field of artificial intelligence that focuses on enabling computers to understand, interpret, and generate human language.
A crucial component of NLP is data annotation, which involves labeling or tagging raw text data with specific information.
This annotated data serves as training material for NLP models, guiding them to learn the nuances of language and perform tasks like machine translation, sentiment analysis, and question answering.
Let’s look at the different aspects of the NLP annotation.
The Importance of High-Quality Annotations
The quality of NLP models is directly tied to the quality of the annotated data they are trained on. Accurate and consistent annotations are essential for teaching models to understand the context, meaning, and intent behind text.
For instance, in sentiment analysis, correctly labeling sentences as positive, negative, or neutral helps models accurately gauge the emotional tone of text.
Common Types of NLP Data Annotation
Some types are:
- Named Entity Recognition (NER): Identifying named entities such as persons, organizations, locations, and dates within text.
- Part-of-Speech Tagging: Assigning grammatical categories (nouns, verbs, adjectives, etc.) to words in a sentence.
- Sentiment Analysis: Determining the sentiment expressed in text (positive, negative, or neutral).
- Relation Extraction: Identifying relationships between entities in text, such as “X works for Y.”
- Coreference Resolution: Resolving references to the same entity within a text, such as pronouns referring to previously mentioned nouns.
- Question Answering: Labeling text with answers to specific questions, aiding in question-answering systems.
Beyond the Basics: Less-Known Annotation Tasks
While the above tasks are commonly associated with NLP data annotation, there are several less-known but equally important ones:
- Dialogue Annotation: Labeling dialogues with information about speakers, intents, and actions to train conversational AI systems.
- Text Summarization: Creating summaries of longer texts, requiring annotators to identify the most important information.
- Machine Translation: Translating text from one language to another, often involving parallel corpora (text in both languages) for annotation.
- Text Generation: Generating new text, such as creative writing or code, based on annotated prompts or examples.
- Text Classification: Categorizing text into predefined categories, such as topic classification or genre identification.
Challenges and Best Practices
NLP data annotation can be a complex and time-consuming process. Some of the challenges include:
- Subjectivity: Many annotation tasks involve subjective judgments, making it difficult to achieve complete consistency among annotators.
- Ambiguity: Natural language can be ambiguous, making it challenging to determine the correct label for certain instances.
- Data Quality: Ensuring the accuracy and consistency of annotations is crucial for training effective NLP models.
To address these challenges, organizations often employ a combination of human annotators and automated tools. Human annotators can provide expert judgment and handle complex cases, while automated tools can streamline the process and improve efficiency.
Additionally, best practices such as clear guidelines, quality control measures, and version control can help ensure the quality and consistency of annotated data.
In conclusion, NLP data annotation is a vital step in building intelligent language-understanding systems. By understanding the different types of annotation tasks and addressing the associated challenges, organizations can create high-quality datasets that enable the development of powerful and accurate NLP models.