
Audio data annotation is the process of labeling audio recordings with specific information to make them machine-readable and usable for training AI models. This involves adding metadata, such as timestamps, speaker identification, and content descriptions, to audio files. While it might seem simple, audio annotation is a complex and crucial step in developing advanced audio-based applications.
Types of Audio Data Annotation:
- Speech-to-Text Transcription: This involves converting spoken words into written text, which is essential for applications like virtual assistants, transcription services, and speech-to-text search.
- Speaker Diarization: This task focuses on identifying and separating different speakers within an audio recording. It’s used in applications like speaker verification, meeting summarization, and audio forensics.
- Keyword Spotting: This involves identifying specific keywords or phrases within an audio recording. It’s used in applications like voice search, call center analytics, and audio surveillance.
- Sound Event Detection: This involves identifying and classifying different types of sounds within an audio environment. It’s used in applications like environmental monitoring, audio surveillance, and smart home devices.
- Sentiment Analysis: This involves determining the emotional tone of spoken language, which is crucial for applications like customer service analysis, market research, and social media monitoring.
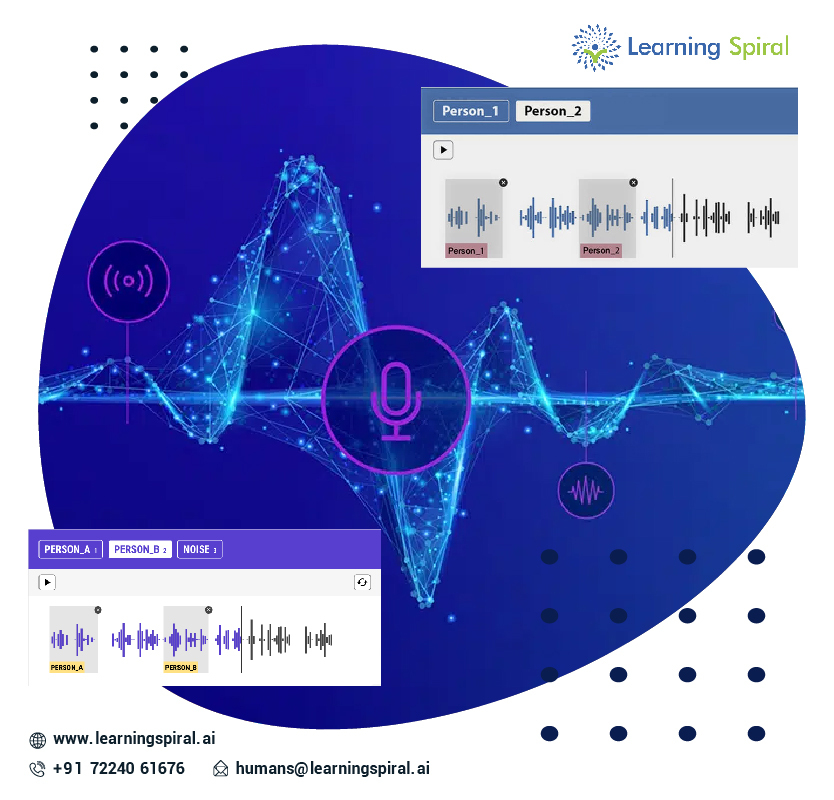
Challenges in Audio Data Annotation:
Audio data annotation presents unique challenges compared to other forms of data annotation. These include:
- Noise and Background Interference: Background noise can significantly impact the accuracy of audio annotations.
- Accents and Dialects: Different accents and dialects can pose challenges for speech-to-text transcription and speaker identification.
- Overlapping Speech: When multiple people speak simultaneously, it can be difficult to accurately transcribe or label the audio.
- Data Volume: Audio datasets can be large and require significant computational resources for processing and annotation.
Applications of Audio Data Annotation:
The applications of audio data annotation are vast and diverse. Some of the most prominent include:
- Virtual Assistants: Audio data is used to train virtual assistants to understand and respond to voice commands.
- Speech Recognition: Accurate speech-to-text conversion is essential for applications like dictation software and transcription services.
- Audio Search: Searching for specific audio content, such as music or podcasts, relies heavily on audio data annotation.
- Audio Surveillance: Identifying and categorizing sounds in audio recordings can be used for security and surveillance purposes.
- Language Learning: Audio data annotation can be used to create interactive language learning tools.
Audio data annotation is a critical component of the AI revolution. By providing accurate and comprehensive labeled data, we can develop more sophisticated and intelligent audio-based applications that enhance our lives in countless ways.
Would you like to know more about specific audio annotation tools or techniques? Learning Spiral AI will answer all the related queries and more. Just comment below.




